building a safer workflow for avoiding duplicate content in large sites with linux server operations: maintenance guide
a reliable linux server operations setup is less about clever code and more about repeatable habits. in this guide, we look at avoiding duplicate content in large sites on a single vps and keep the steps focused on production work.

security and maintenance notes
write the final notes immediately after the change ships. include the reason for the change, the files touched, the command used, and the metric that improved. this turns a one-time fix into reusable team knowledge.
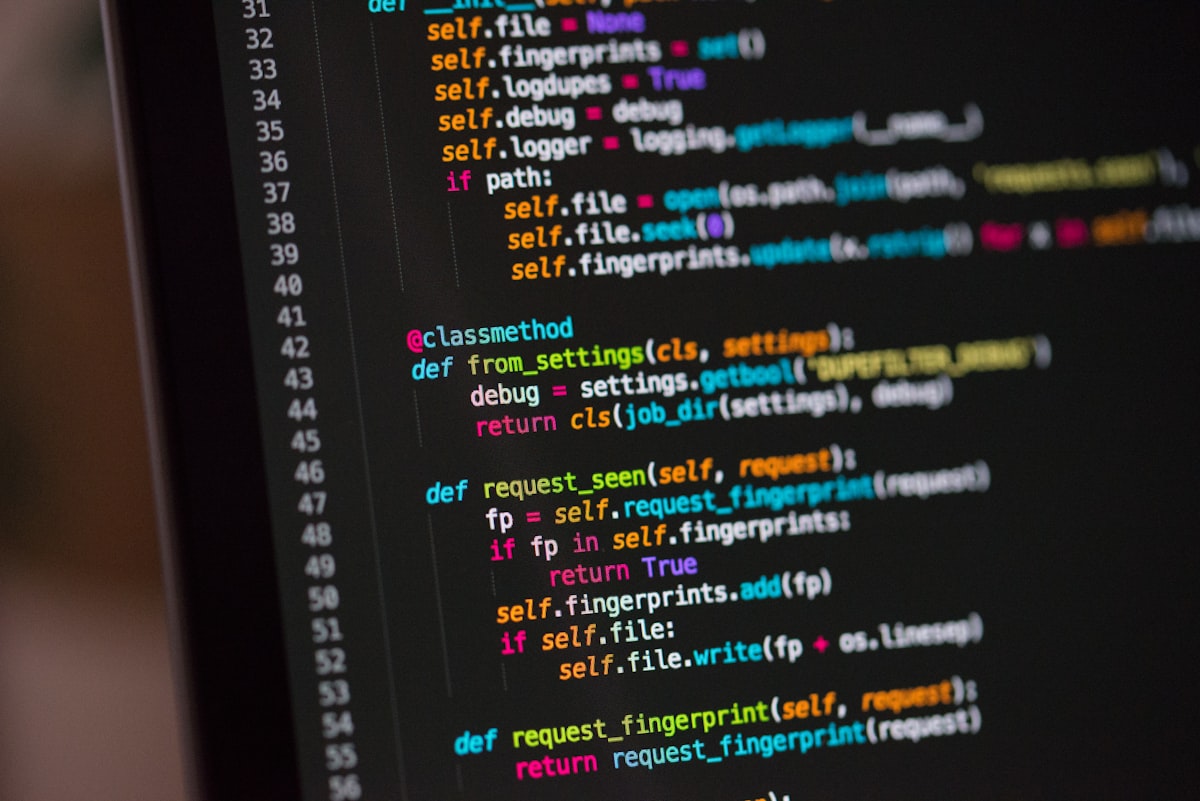
a good production pattern has a small surface area. it should be easy to test, easy to disable, and easy to explain to another developer in a few minutes.
systemctl status app.service
journalctl -u app.service -n 100 --no-pagerimplementation checklist
- capture the current behavior
- create a safe backup
- test the smallest change
- watch logs after release
- write the final note
final notes
the best result is not only a faster or cleaner linux server operations implementation. it is a change that another developer can inspect, understand, and safely repeat. keep the final commands, metrics, and assumptions close to the article so future maintenance is easier.